
Why AI PM interviews are different from traditional PM rounds
On the surface an AI PM round looks like a traditional PM interview. You’ll still get product-sense questions, strategy questions, behavioural questions, and metric questions. But the actual content is different in ways that catch most candidates off guard.
In a traditional PM round you walk through CIRCLES or RICE. In an AI PM round you’re expected to reason about model accuracy versus precision, decide when generative AI is the wrong tool for a problem, defend an A/B test design for a personalised feature, and explain to a non-technical stakeholder why your model hallucinates. The companies hiring most aggressively for AI PMs in India in 2026 — Microsoft India, Google India, Razorpay, Cred, Swiggy, Zomato, Sarvam AI, Krutrim, Fractal — all interview against a different bar than five years ago.
This guide walks through 30+ questions you’re most likely to face, with sample answers that reflect how senior AI PMs actually frame responses in real interviews. Each answer is short, structured, and built to be adapted to your own experience. Read it through once. Then practise the answers out loud — 60% of candidates know the material but lose the offer on communication and structure. More on that at the end.
AI and ML fundamentals every PM must know
1. What is the difference between AI, machine learning, and deep learning?
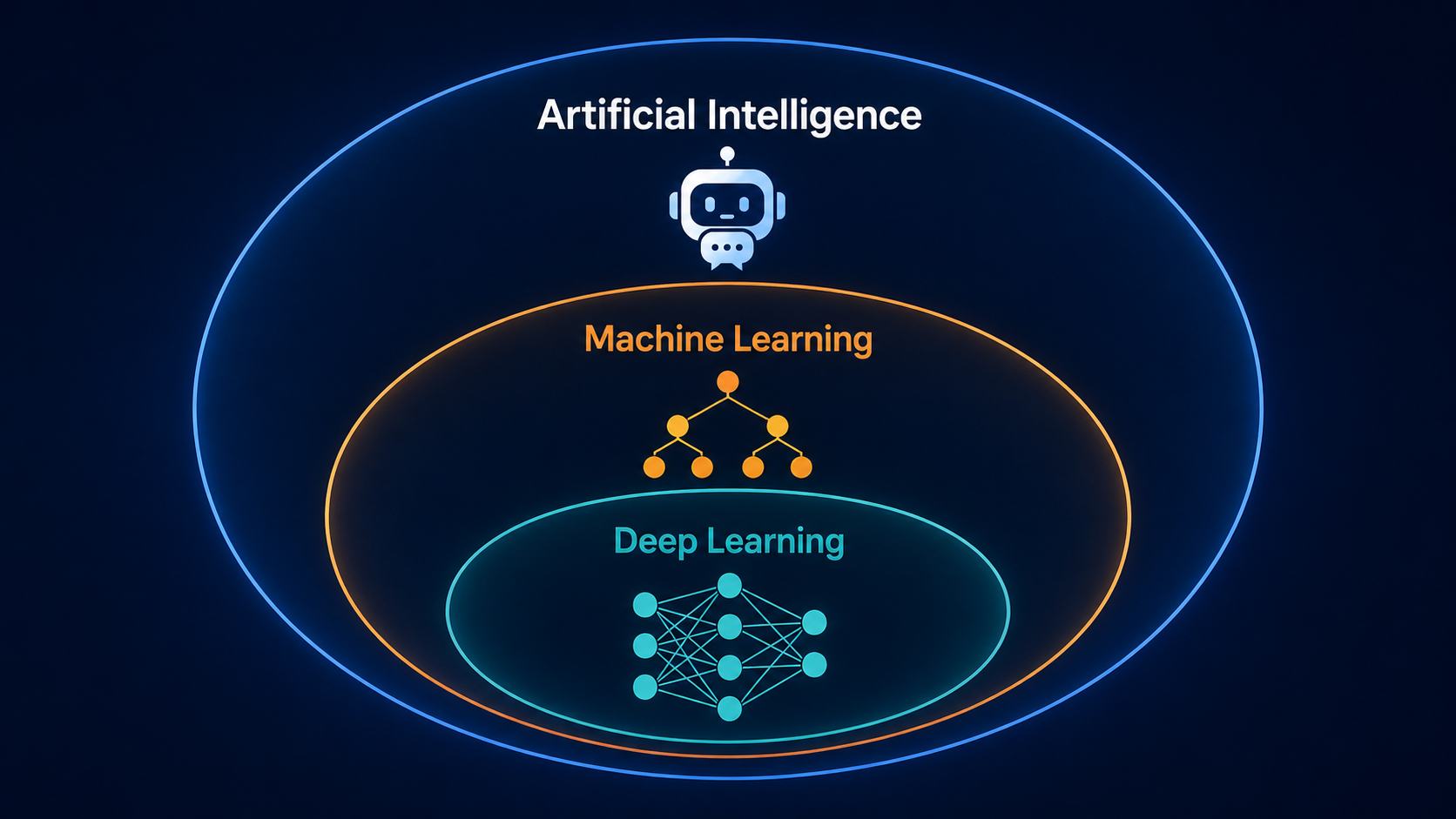
AI is the broad goal of getting machines to perform tasks that typically require human intelligence. Machine learning is a subset of AI where systems learn patterns from data instead of being explicitly programmed. Deep learning is a subset of machine learning that uses multi-layered neural networks to handle complex patterns in unstructured data like images, audio, and language. As a PM, what matters is knowing which one your problem actually needs — most product problems are solved with classical ML, not deep learning.
2. Explain supervised versus unsupervised learning with examples
Supervised learning uses labelled data — the model learns from input-output pairs. Examples: spam detection, credit scoring, fraud detection. Unsupervised learning works on unlabelled data and finds patterns on its own. Examples: customer segmentation, anomaly detection, topic clustering. As a PM, your data availability often decides which one is viable. If your team doesn’t have labelled training data, supervised is off the table until labelling cost is solved.
3. What is a foundation model and why does it matter for product strategy?
A foundation model is a large pre-trained model — like GPT-4, Claude, Llama, or India’s Sarvam — that can be adapted to many downstream tasks. They matter for product strategy because they collapse the build-versus-buy decision. Five years ago you built ML models from scratch. Today you decide whether to fine-tune a foundation model, use it via API, or train from scratch — each choice has different cost, latency, accuracy, and IP implications.
4. How does fine-tuning differ from prompt engineering?
Prompt engineering means crafting better instructions for an existing model — cheap, fast, no training. Fine-tuning means continuing to train the model on your specific data — expensive, slower, but better for narrow, high-accuracy use cases. RAG sits between them. As a PM, the rule of thumb is: start with prompt engineering, move to RAG if you need domain knowledge or freshness, and fine-tune only when accuracy gaps justify the cost.
5. What is Retrieval-Augmented Generation (RAG) and when would you use it?
RAG combines a language model with a search system. When a user asks a question, the system first retrieves relevant documents from your knowledge base, then feeds them to the language model to generate an answer grounded in those documents. You use RAG when you need the model to answer about proprietary, frequently updated, or domain-specific information that a base model wouldn’t know — internal documentation, product catalogues, customer support knowledge bases.
6. What is model drift and how do you detect it post-launch?
Model drift is when a model’s accuracy degrades over time because the real-world data has shifted from what it was trained on. You detect it by tracking the difference between training-data distributions and live-traffic distributions, monitoring prediction confidence over time, and tracking key business metrics that the model influences. As a PM, you don’t need to detect drift yourself — but you need to make sure your roadmap includes monitoring and retraining cycles.
7. Explain the bias-variance tradeoff in product terms
A high-bias model makes oversimplified predictions and misses patterns. A high-variance model fits the training data too tightly and breaks on new data. In product terms, high bias gives you a model that’s confidently wrong for many users, high variance gives you a model that performs brilliantly in testing and fails in production. Most production models aim for the sweet spot — and most PM mistakes happen when you optimise for offline accuracy and ignore real-world variance.
8. What is the difference between predictive AI and generative AI use cases?
Predictive AI forecasts an outcome from input data — credit score, churn risk, fraud probability, recommendation rank. Generative AI creates new content — text, images, code, audio. They have very different product trade-offs. Predictive AI is mature, measurable with clear accuracy metrics, and lower regulatory risk. Generative AI is newer, harder to evaluate, prone to hallucinations, and carries higher trust and IP risk. Most products in 2026 combine both.
Here’s another resource you’ll find useful: 30+ AI Product Manager Interview Questions With Sample Answers (2026 Edition).
AI product strategy and roadmapping

9. How do you decide between building an AI feature in-house versus using a vendor API?
Three factors decide it — accuracy needs, cost at scale, and strategic IP. If accuracy needs are high and the use case is narrow, in-house wins because you can fine-tune. If cost-per-call is high and volume is huge, in-house wins because vendor APIs get expensive at scale. If the AI capability is core to your competitive moat, in-house wins for IP. For most other cases — early-stage products, supporting features, anything not on your core path — vendor APIs are faster and cheaper.
10. Walk me through how you would build a roadmap for an AI-first product
I’d start with the user problem, not the technology. Map the user journey, identify the highest-friction moments, and ask which of those can be improved with prediction, personalisation, or generation. Then evaluate each opportunity on impact, data readiness, model feasibility, and time-to-value. The roadmap sequences low-risk, high-value wins early (recommendations, search) and reserves higher-risk bets (autonomous agents, generative features) for later when trust and data infrastructure are stronger.
11. How do you prioritise AI features when model accuracy is uncertain?
I prioritise on expected value, not certain value. For each feature I estimate the probability the model hits the accuracy threshold, the impact if it does, and the cost if it doesn’t. Features where even a 60% accurate model creates user value go first. Features that need 95%+ accuracy to be useful — like medical diagnosis or financial advice — go later, when data and infrastructure are ready. The key is sequencing for learning, not just for impact.
12. What is your framework for in-house ML team versus vendor APIs?
I use a three-question test. First — does this use case need accuracy beyond what off-the-shelf APIs deliver? Second — will our annual API spend exceed the cost of a small ML team? Third — is this capability part of our long-term differentiation? Two yeses out of three pushes me towards in-house. One or fewer keeps it on vendor APIs. The mistake most PMs make is building ML teams too early, before the use case is validated.
13. How do you communicate AI capabilities and limitations to non-technical stakeholders?
I avoid model-internal language entirely. Instead I describe what the system will and won’t do in terms of user experience and business outcomes. “This will correctly identify fraudulent transactions 90% of the time, miss 10%, and flag a small number of legitimate transactions for manual review” lands better than “This is a gradient boosted classifier with 0.91 F1 score.” Set expectations early, and always pair every capability claim with its corresponding failure mode.
14. How do you avoid the AI hype trap in product strategy?
By starting with the problem, not the technology. Every “we should add AI to X” idea should pass a simple test — would a user notice or care about this if I didn’t tell them AI was involved? If the answer is no, AI is the wrong tool. The hype trap is when teams build AI features that demo well but don’t move user metrics. Strategic AI work is invisible to users and visible in their behaviour.
Identifying and prioritising AI use cases
15. Walk me through how you would identify AI use cases in our product
I’d run a structured discovery — start with user research and customer support tickets to find patterns of friction, look at funnel data to find where users drop off, talk to operations teams to find manual work that scales poorly. From there I’d map each opportunity against three filters — is there enough data, is the impact measurable, and is the cost of being wrong manageable? The use cases that pass all three become candidates for AI investment.
16. What criteria do you use to evaluate whether a problem is suitable for AI?
Five questions. Is there a pattern in historical data? Is the input-output relationship consistent enough to learn? Is there enough labelled data, or can it be generated cheaply? Is the cost of a wrong prediction acceptable? And is there a human-in-the-loop fallback if the model fails? If even one of these is a no, AI probably isn’t the right tool — or it needs significant scaffolding before it can be deployed safely.
17. How would you size the impact of an AI feature before building it?
I’d take a baseline metric — say, conversion rate — estimate the improvement an AI version of the feature could deliver based on benchmarks or industry data, and multiply through user volume and economic value. For a recommendation system on a 100,000 monthly active user product, a 5% lift on a 3% baseline conversion translates to specific revenue. I always show two scenarios — base case and downside — and frame the bet in terms of expected value, not promised value.
18. Give me an example of a problem where AI is not the right solution
Customer support routing in a low-volume early-stage product. The data needed to train a routing model doesn’t exist, the cost of being wrong is high (frustrated customer), and a simple rule-based system handles 90% of cases reliably. Building AI here would be slower, more expensive, and worse than rules. AI should be reserved for problems where the volume justifies the investment, the data exists, and the user benefit is meaningful.
19. How do you sequence AI feature rollouts in a product?
I sequence on three axes — risk, learning, and dependency. Lowest-risk features ship first to build user trust and team confidence. Features that generate the most learning about user behaviour ship next, because they inform later features. Features that depend on infrastructure or data from earlier features ship last. Skipping this sequencing is how AI products end up with a flagship feature that’s brilliant in isolation but never adopted because the foundational work wasn’t done.
Data, metrics, and A/B testing for AI products

20. What metrics matter most for an AI product feature?
<span style=”font-weight: 400;”>Three layers. Model metrics — accuracy, precision, recall, latency — to verify the model works. Product metrics — engagement, retention, conversion — to verify the feature creates user value. Business metrics — revenue, cost-to-serve, lifetime value — to verify the feature creates company value. Most PM mistakes happen at the gap between layers. A model can have 95% accuracy and zero product impact, or a 70%-accuracy model can drive significant business value. All three layers matter.
21. How do you A/B test AI features that personalise differently for each user?
Standard A/B tests work, but you have to design them carefully. The treatment group sees the AI-personalised version, the control sees the baseline (rules-based or random). You measure aggregate outcomes, not per-user predictions, since each user’s personalisation is unique. Watch out for novelty effects — AI features often beat baseline in week one and regress in week four. Run tests for at least four weeks and segment by user cohorts to spot heterogeneity.
22. What is a confusion matrix and how does it inform product decisions?
A confusion matrix shows the four ways a binary prediction can be right or wrong — true positive, true negative, false positive, false negative. It informs product decisions because different errors have different costs. In a fraud detection product, a false negative (missed fraud) costs more than a false positive (flagging a good transaction). In a recommendation product, the cost equation flips. As a PM you tune the model’s threshold based on which error you can least afford to make.
23. How do you measure user trust in an AI feature?
Indirect signals — repeat usage rates, override rates (how often users reject the AI’s suggestion), feedback ratings, support tickets mentioning the feature. Direct signals — qualitative interviews and trust-scale surveys. Trust takes longer to build than usage. Many AI features show high adoption in week one because users try them, then collapse in week three because users don’t trust the output. Tracking trust separately from usage prevents that misread.
24. How do you balance offline ML metrics with online business metrics?
Offline metrics tell you whether the model can learn the task. Online metrics tell you whether the feature creates value. Always run both. A common failure mode is shipping a model with great offline accuracy that doesn’t move online metrics because the offline test set didn’t reflect real-user behaviour. The fix is closing that loop — feed online behaviour back into the training pipeline so offline tests become more representative of production.
AI ethics, bias, and risk management
25. How do you identify and mitigate bias in an AI product?
Start at data — audit training data for representation gaps across demographic groups. Then audit model outputs — measure prediction differences across the same groups in test data. Then audit user-facing outcomes — measure whether the deployed feature creates equal value for all user segments. Mitigation happens at all three layers — diversify training data, add fairness constraints to the model, and add product-level guardrails like human review for high-impact decisions. Bias work is not one-time, it’s continuous.
26. What is responsible AI and how does it translate to product practice?
Responsible AI is the principle that AI systems should be fair, transparent, accountable, and aligned with user wellbeing. In product practice it shows up as four habits — disclose to users when AI is involved in a decision that affects them, give them a way to challenge or override AI outputs, monitor for harmful outcomes proactively, and document model decisions so they can be audited later. These aren’t nice-to-haves in 2026 — they’re increasingly regulatory requirements.
27. How do you handle hallucinations in generative AI features?
Three tactics. First, design the feature so hallucinations are visible and correctable — show sources, allow editing, never present generated content as final without user review. Second, ground the model in trusted data using RAG. Third, evaluate every release against a hallucination benchmark and set release thresholds. The product mistake is assuming hallucinations can be eliminated. They can’t — they can only be reduced and contained.
28. What governance and compliance issues are you watching in AI right now?
In India — the proposed Digital India Act and its AI-specific provisions, RBI’s draft guidelines on AI use in financial services, and IT ministry advisories on training data and synthetic content disclosure. Globally — the EU AI Act, US executive orders on AI safety, and emerging copyright cases on training data. As a PM, you don’t need to be a lawyer, but you need to know what’s in flight so your roadmap doesn’t get blindsided by a compliance change six months out.
Related read: How to Explain Gaps in Your Resume: What Hiring Managers Actually Want to Hear.
Behavioural questions unique to AI PM roles
29. Tell me about an AI product you shipped. What worked and what didn’t?
Structure your answer in four parts — the user problem you were solving, the AI approach you chose and why, what the model did well and badly in production, and what you’d do differently. The mistake most candidates make is over-indexing on the wins. Senior interviewers want to hear the post-launch failure modes — the bias issue you didn’t catch, the edge case the model broke on, the metric that didn’t move. The story of what didn’t work tells them more about how you think than the story of what did.
30. Describe a time you had to push back on an engineer or data scientist
Pick a story where you disagreed on a technical decision that had product implications — model choice, accuracy threshold, launch timing — and you held your ground based on user data, not authority. Walk through how you framed the disagreement, the evidence you brought, and how you reached resolution. Senior interviewers are testing whether you can collaborate with technical partners as a peer, not whether you can win arguments.
31. Tell me about a time the AI model didn’t perform as expected post-launch
Choose a real failure and own it without making excuses. Describe what you saw in the metrics, what you discovered when you investigated, what immediate action you took, and what longer-term changes you made to the development process. The point of this question is to test your post-launch instincts — can you spot a problem, diagnose it, contain it, and learn from it. Generic “we monitored and retrained” answers fail. Specific, traceable failures with clear lessons land.
32. How do you stay current on the AI landscape?
Show that you have a structured habit, not random scrolling. Mention specific newsletters (Lenny’s, AI Snake Oil, Latent Space), conferences you follow (NeurIPS, ICLR), papers you read (with at least one specific recent example), and Indian voices you track (Sarvam team, Krutrim, Pratham Prasoon). The point isn’t to recite a list — it’s to show you have a way of separating signal from noise in a space that moves fast.
Case study: a real AI PM interview round walkthrough
Imagine you’re interviewing for an AI PM role at an Indian fintech startup. The hiring manager opens with: “We’ve seen a 30% jump in fraudulent transactions over the last quarter. We’re considering building an AI-powered fraud detection system. Walk me through how you’d approach this as the AI PM.”
Strong candidates structure their response in five moves.
First — clarifying questions. What’s the current fraud rate baseline? What’s the cost of each fraudulent transaction? What’s the cost of falsely flagging a legitimate transaction (customer friction, support load)? Is this card fraud, account takeover, or something else? Asking these signals you understand that AI is the answer to a specific question, not a general direction.
Second — framing the metric. False negatives (missed fraud) cost direct money. False positives (flagged legitimate transactions) cost customer trust and support cost. Define the target — for example, catch 90% of fraud while keeping false-positive rate under 1%. This becomes the model’s north star.
Third — solution sketch. Start with a simple rules-based system as the baseline — known patterns, velocity checks, IP and device fingerprints. Layer a supervised ML model trained on historical fraud cases. Eventually add real-time scoring and feedback loops where flagged transactions reviewed by humans get fed back into the training data.
Fourth — sequencing. Ship the rules system first. Build the ML model on the second sprint. Run the ML model in shadow mode (predicting but not blocking) for four weeks to validate. Then graduate to active scoring with a human-in-the-loop review queue. This sequencing reduces risk while building team confidence.
Fifth — success measurement. Track three layers — model metrics (precision and recall), product metrics (false-positive friction reported by support, customer churn), business metrics (fraud loss reduction, net revenue impact). Set a 90-day review point to decide on further investment.
That five-move structure — clarify, frame, sketch, sequence, measure — works on almost any AI PM case prompt. Memorise it. Practise it.
How to prepare for AI PM interviews with mock practice
Reading interview answers is not the same as being able to deliver them under pressure. The pattern across hundreds of AI PM interviews is consistent — candidates who know the content but haven’t practised delivery lose to candidates with weaker content who’ve practised speaking it out loud.
GroYouth’s GY FIT platform is built for this exact problem. It runs you through AI-powered mock interviews tailored to AI PM roles, scores your communication, confidence, and structure, identifies the gaps in your delivery, and gives you specific feedback on what to improve before the real interview. Most candidates need three to five mock rounds before they’re truly ready.
Start with a free mock interview on GY FIT, then layer practice with peers, friends, or career counsellors on GroYouth’s GY Coach service. By the time you walk into the real round, the answers should feel automatic — not memorised, but internalised.
Try a free AI Product Manager mock interview on GY FIT →]
Frequently asked questions
What does an AI Product Manager do that a regular PM doesn’t?
An AI PM owns the product strategy, roadmap, and outcomes for features powered by AI or machine learning. The day-to-day is similar to a regular PM, but the technical depth is different — they make decisions about model accuracy thresholds, data quality, A/B test design for personalised features, and risk management for AI-specific failure modes like bias and hallucination.
Do I need a computer science or ML degree to become an AI PM?
No, but you need working fluency in AI concepts. Most successful AI PMs are not ML engineers — they’ve learned enough to make informed trade-offs, communicate with technical teams, and reason about model behaviour. Online courses, hands-on projects, and shipping AI features as a PM in your current role are all valid paths.
What salary can an AI PM expect in India in 2026?
AI PM salaries in India typically range from ₹25 to ₹60 LPA for mid-senior roles at product companies, with senior and staff-level roles at unicorns and global tech companies going from ₹60 LPA to ₹1.5 crore including equity. Salaries vary significantly with company stage, location, and the candidate’s technical depth.
Which Indian companies are hiring AI Product Managers?
Major Indian hirers in 2026 include Microsoft India, Google India, Razorpay, Cred, Swiggy, Zomato, Flipkart, Meesho, PhonePe, Sarvam AI, Krutrim, Fractal, Mu Sigma, and a long tail of AI-native startups. Global companies with India teams — OpenAI, Anthropic, Adobe, Salesforce — are also active hirers.
How long should I prepare before an AI PM interview?
Plan for four to eight weeks of focused preparation if you’re transitioning from a traditional PM role. The first two to three weeks should be content learning (AI concepts, frameworks, case studies), and the rest should be mock practice — including AI-powered mock interviews on tools like GY FIT to refine your delivery.
Is AI PM a future-proof career path?
AI PM is one of the fastest-growing PM specialisations in 2026 and will remain so for the next decade. As more products embed AI capabilities, the demand for PMs who can navigate AI-specific trade-offs is increasing across every industry, not just tech.
What is the difference between an AI PM and an ML PM?
The terms are often used interchangeably, but in practice ML PM tends to focus on traditional machine learning products like recommendations, search, and predictive systems, while AI PM has broader scope including generative AI, foundation models, and agentic systems. Most modern roles are framed as AI PM regardless of the specific technology stack.
Can I transition from traditional PM to AI PM?
Yes, and this is the most common path into AI PM roles. The transition requires building working fluency in AI concepts, getting hands-on exposure to AI features in your current product, and demonstrating in interviews that you can reason about AI-specific trade-offs. Many candidates make the switch within their current company before moving externally.
